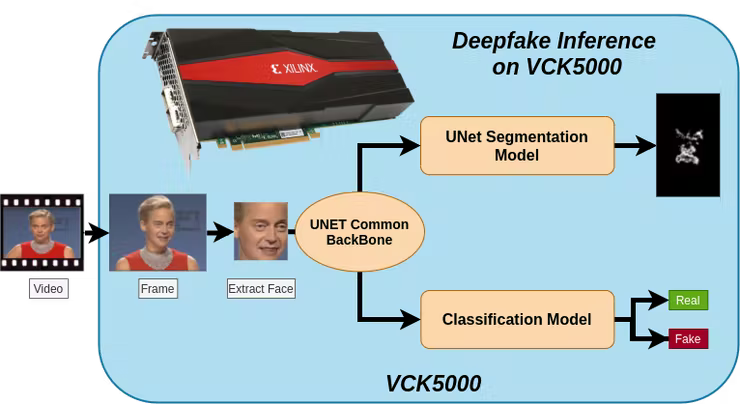
DEEPFAKE CLI: Accelerated Deepfake Detection Using FPGAs
Omkar Bhilare*, Rahul Singh*, Vedant Paranjape*, and 3 more authors
In Parallel and Distributed Computing, Applications and Technologies, 2023
Because of the availability of larger datasets and recent improvements in the generative model, more realistic Deepfake videos are being produced each day. People consume around one billion hours of video on social media platforms every day, and that’s why it is very important to stop the spread of fake videos as they can be damaging, dangerous, and malicious. There has been a significant improvement in the field of deepfake classification, but deepfake detection and inference have remained a difficult task. To solve this problem in this paper, we propose a novel DEEPFAKE C-L-I (Classification - Localization - Inference) in which we have explored the idea of accelerating Quantized Deepfake Detection Models using FPGAs due to their ability of maximum parallelism and energy efficiency compared to generalized GPUs. In this paper, we have used light MesoNet with EFF-YNet structure and accelerated it on VCK5000 FPGA, powered by state-of-the-art VC1902 Versal Architecture which uses AI, DSP, and Adaptable Engines for acceleration. We have benchmarked our inference speed with other state-of-the-art inference nodes, got 316.8 FPS on VCK5000 while maintaining 93% Accuracy.
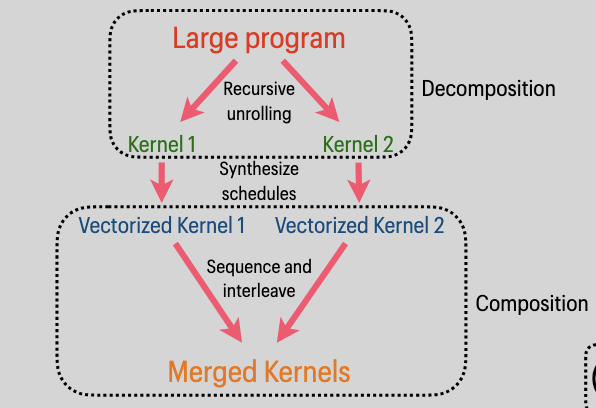 Biscotti: An Approach to Parallel Scheduling for Vectorized Encrypted Arithmetic Circuits2025Poster presented at The Midwest Programming Languages Summit (MWPLS), December 2025
Biscotti: An Approach to Parallel Scheduling for Vectorized Encrypted Arithmetic Circuits2025Poster presented at The Midwest Programming Languages Summit (MWPLS), December 2025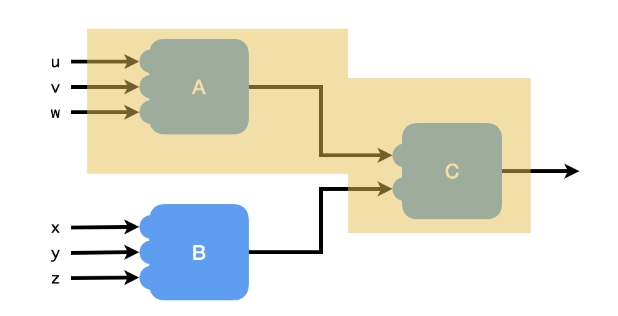
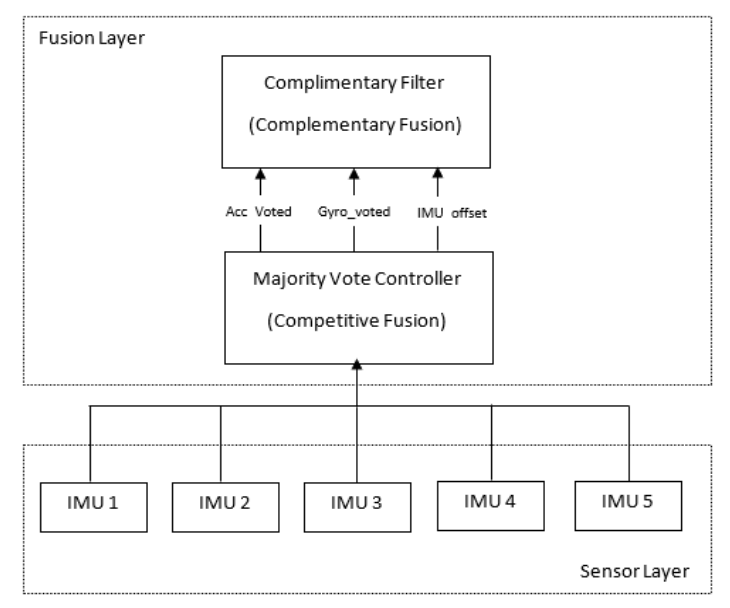 Sensor Fusion Devs for Angle Estimation on Inertial Measurement UnitIn 2023 Winter Simulation Conference (WSC), 2023
Sensor Fusion Devs for Angle Estimation on Inertial Measurement UnitIn 2023 Winter Simulation Conference (WSC), 2023